
ECIR 2011
https://link.springer.com/chapter/10.1007/978-3-642-20161-5_34
https://ink.library.smu.edu.sg/cgi/viewcontent.cgi?article=2374&context=sis_research
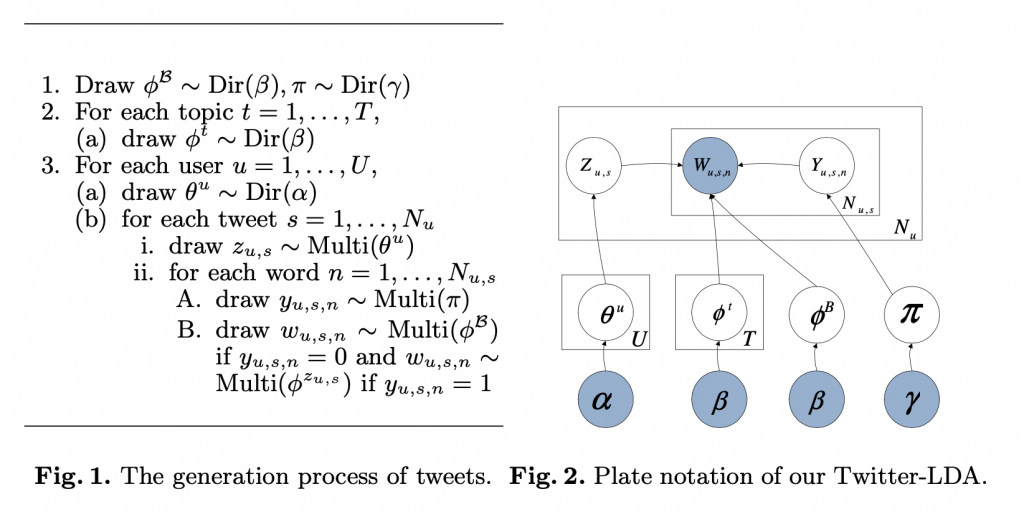

q* 獲得的方式為
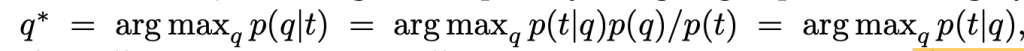
p(t) 沒有意義移除,又假設每個標籤的重要性均等,得到最右邊的式子。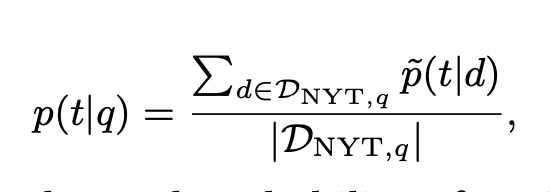
p(t|q) 如上式計算可獲得。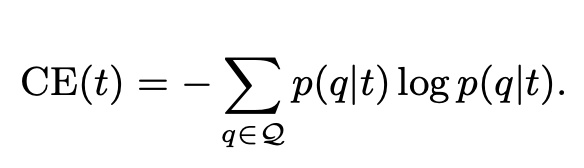
t)和 NYT 主題 (t')可得 散度如下
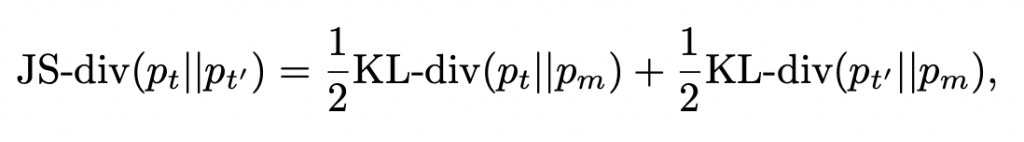
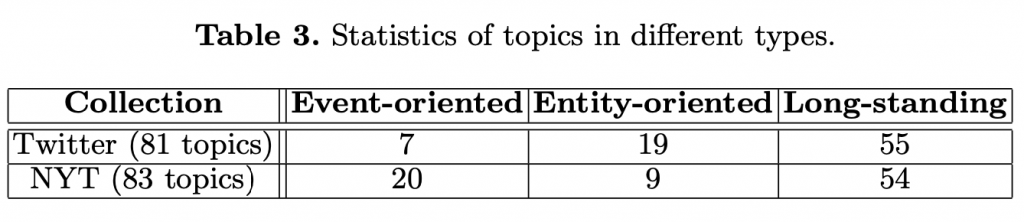
[未完待續]
